Back in 2014, my friend Alastair Porter and I built a thing called Spinbin. The idea was simple and, at the time, slightly ridiculous: if a radio station’s website showed the tracks it had just played, we should be able to turn that into a subscribable playlist. The tagline we gave it — “Turning the web into playlists… one page at a time” — feels a bit on-the-nose in retrospect, but it captured the ambition.
Spinbin worked. It scraped Pitchfork’s Best New Tracks, NPR’s All Songs Considered, Billboard’s Hot 100, and a few others. It spat out XSPF files that you could subscribe to in Tomahawk — the spiritual predecessor to Parachord. When the source page updated, the playlist updated, and Tomahawk pulled in the new tracks. Magic… ish.
Then, in early 2018, the service we depended on for actual scraping — a company called Kimono — shut down. Within a few days, Spinbin went from “auto-updating radio playlists for your music player” to “a domain that no longer does anything.” And that’s where it sat for the next 7 years.
I want to tell you why it’s back, and how it works now.
The Missing Primitive
The reason Spinbin stopped being interesting isn’t just that Kimono died. It’s that the consumer side of the loop was broken too. Tomahawk development had stopped. The idea of a music player that could resolve playback across whatever services you used — the thing that made subscribing to a scraped XSPF actually useful — disappeared. XSPF itself became an obscure format, kept alive mostly by VLC.
Fast-forward to today. We have Parachord (on Mac, Windows, Linux and now Android. We have a parachord:// protocol that any web page can use to import a playlist from a URL. We have a resolver pipeline that takes a track name and figures out how to play it from whatever music sources you’ve configured — Spotify, Apple Music, Bandcamp, YouTube, local files, all of it.
In other words: the missing primitive for 2014-Spinbin is exactly what Parachord has become in 2026. The reason to resurrect this idea isn’t nostalgia. It’s that the consumer experience finally exists again to make it worthwhile.
The Bridge: Describe What, Not Where
To understand why this combination works, it helps to talk about XSPF (pronounced “spiff”) for a minute, because it’s a specific choice that does specific work.
If you’ve ever subscribed to a podcast by URL, you already understand 90% of the shape. A podcast is just an RSS feed: an XML document at a stable URL that lists episodes. Your podcast app fetches it, caches the episode list, downloads audio, and polls the feed later for new episodes. The publisher doesn’t care whether you use Overcast, Apple Podcasts, Pocket Casts, or a terminal-based feed reader — they publish the feed once, and anyone with a compliant client can consume it. That openness is the entire reason podcasting survived twenty years without being captured by a platform (although the platforms are actively trying to change that).
XSPF is the same shape, but for music playlists. A subscribable XML document at a stable URL that lists tracks. Any compliant client can consume it. The publisher doesn’t care what music player you use. The contract is simple and open. A Spinbin XSPF is to Parachord what an RSS feed is to Overcast: a plain file somewhere on the web that your app subscribes to and updates against.
There’s one crucial difference, and it turns out to be the most interesting thing about the format. Podcast RSS points at a concrete audio file — every <item> has an <enclosure url="...mp3">. The feed is self-contained. XSPF doesn’t. XSPF is an open playlist format, originally drafted in 2005 by the XSPF Working Group, and critically, it describes tracks symbolically — by title, artist, and album — rather than by a concrete URL to an audio file. A Spinbin XSPF entry looks like this:
<track>
<title>Vampire Empire</title>
<creator>Big Thief</creator>
<album>Double Infinity</album>
</track>
Notice what’s not there: there’s no Spotify URI, no S3 link to a specific MP3, no YouTube video ID, no path to a file on disk. Just the name of the thing.
That absence is the feature. Every other common playlist format pins you to a specific source:
- M3U and PLS point at file paths or stream URLs — closer to podcast RSS in spirit, which works because podcast episodes live outside of paywalls. Music doesn’t.
- Spotify’s playlist export is a list of Spotify URIs. Exporting doesn’t help if you move to Apple Music.
- Apple Music playlists live inside Apple’s ecosystem and are hard to get out.
- Even the “universal” music-link aggregators (Odesli, Songwhish, etc.) are per-track redirectors; they don’t give you portable, downloadable documents.
XSPF opts out of the whole question. It says: here is what to play, in what order. Figuring out where to play it from is somebody else’s problem. This is where the podcast analogy breaks down in XSPF’s favor. A podcast episode is singular — one MP3, one host, one URL. A music track is plural — it lives on Spotify, on Apple Music, on Bandcamp, on YouTube, on your hard drive, sometimes all at once. An audio-URL-in-the-feed approach would force a playlist publisher to pick one of those sources and strand every listener who uses a different one. Keeping the feed symbolic lets a single XSPF serve every kind of listener.
That “somebody else” is what Parachord calls content resolution, and it’s the other half of the puzzle. Parachord takes a symbolic description — “Big Thief / Vampire Empire” — and walks through every source every listener has configured in priority order: your local FLAC library, Bandcamp if you own it, Spotify if you subscribe, Apple Music if that’s your thing, YouTube as a fallback. The first source that can produce that track wins. Same playlist, different playback path per listener.
The consequence is that a XSPF playlist is portable across services in a way a Spotify link never can be. A Spinbin XSPF of “what KEXP played yesterday” is:
- A ripping session for a local-library purist, who plays each track from their own FLAC collection (or identifies new things to buy).
- A Bandcamp-first listening session for someone who wants to support artists directly.
- A Spotify queue for a streaming-service subscriber.
- A YouTube-backed stream for someone who hasn’t configured anything else.
- Some mixture of all four, resolved per-track, for anyone with a typical multi-source setup.
The XSPF file doesn’t know any of that. It can’t — it’s a static document served from GitHub Pages. It doesn’t have your credentials, doesn’t know what’s in your library, doesn’t know what services you subscribe to. That information lives entirely on your machine, inside Parachord. And that’s exactly right: the scraping side is service-agnostic on purpose, and the playback side is credential-rich on purpose, and the line between them is a ~2KB XML file.
This separation is also what makes Spinbin durable. If tomorrow Spotify goes away and Parachord swaps it out for something new, the same XSPF files keep working — the resolution layer handles the change. If a user mirgrates from one streaming service to another - or abandons streaming entirely for their own local library - it still “just works”. If KEXP migrates to a different API, the scraper changes, but the XSPF output doesn’t. The playlist-subscription contract is stable in the middle, and everything around it can evolve.
This is also why parachord://import?url=... exists as a first-class protocol verb. Importing a URL that points to an XSPF isn’t a niche feature; it’s the primary way Parachord accepts playlists from the rest of the web. Any site — Spinbin, a record-review blog, a Discord bot, a weekly newsletter, a concert-ticket confirmation page — can publish an XSPF file and offer a one-click path into your music player of choice. The same way podcasting stayed an open medium because nobody owns RSS, playlists can stay an open medium because nobody owns XSPF. The file format has been around for twenty years waiting for enough of the rest of the stack to catch up.
What It Does
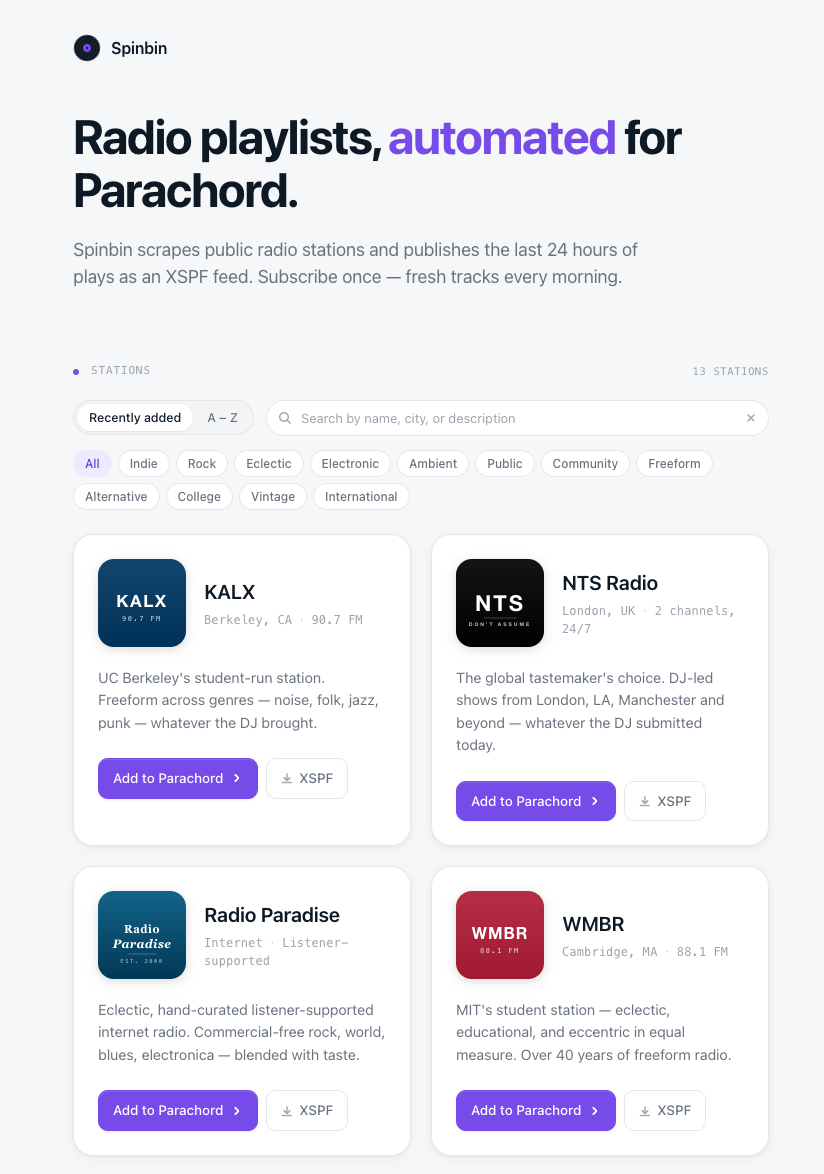
Spinbin is now a public site. It lists a bunch of public radio stations, and for each one it publishes an XSPF file containing the tracks that station played in the last 24 hours, refreshed daily - or what I call Radio Station Rewinds. Click “Add to Parachord” on any card and the stream is in your library forever. Every morning it will update with whatever aired yesterday. Rewinds is a design choice that is not intended to displace your live-streaming experience with these stations - but to complement it and deepen your connection with the curatorial voice of each.
As of this writing, the lineup is:
- KEXP (Seattle, 90.3 FM) — [Everything the music mattered for]
- KCRW (Santa Monica, 89.9 FM) — LA’s eclectic public radio
- WFMU (Jersey City, 91.1 FM) — the longest-running freeform station in the US
- WFUV (NYC Fordham, 90.7 FM) — adult album alternative, Bronx-grown
- WPRB (Princeton, 103.3 FM) — legendary college freeform
- KALX (Berkeley, 90.7 FM) — student-run freeform
- WMBR (MIT Cambridge, 88.1 FM) — eclectic educational
- XRAY.fm (Portland) — community-powered independent radio
- NTS Radio (London) — global tastemaker’s choice
- Radio Paradise — hand-curated listener-supported internet radio
- SomaFM: Groove Salad — ambient, downtempo, beats
- SomaFM: Indie Pop Rocks! — new and classic indie pop
- Bagel Radio (San Francisco) — alternative rock for adults
- Vintage Obscura — rare vintage tracks from around the world, curated by Reddit
Some of these stations are personal taste influencers that I’ve been listening to for 20 years. Some I’d never heard of before I went looking for independent and public radio stations with a scrapeable playlist. The point is: they all programmed a specific set of songs today, and now you can listen to the whole thing, in order, in your music player of choice, without caring what streaming service has what track. Human curation that is portable to wherever you fulfill your music from.
Spinbin is one application of a general pattern, not a special case. The recipe — compose a list of tracks, serialize it to XSPF, publish it anywhere on the web, and hand listeners a
parachord://import?url=...button — works for any music experience you’d want to build. A record-review blog where every album mention is a playable playlist. A festival lineup that imports as a pre-show listening guide. A “what’s on the café speakers right now” feed. A friend’s weekly mixtape hosted on their personal site. A Discord bot that exports!mixcommands as subscribable playlists. A year-in-review recap that’s actually listenable. Theparachord://protocol handles the last mile into the listener’s player of choice. You just have to know what songs work well together (or find other curators that do) — and Spinbin is just one of my particular answers to that question.
How It Works Now (the nerdy stuff)
The 2014 Spinbin was a Tornado web app backed by SQLite, deployed as a Docker container somewhere that cost money. The 2026 Spinbin is:
- A daily GitHub Actions cron (
0 10 * * *) - One
generate.pyscript that runs about 14 scrapers - A handful of XSPF files pushed to the
gh-pagesbranch - A static HTML index page deployed alongside them
That’s it. No database. No server. No credentials to rotate. The entire infrastructure is $0/month, and if I walked away from it tomorrow the playlists would still update at 5 AM EST every day for as long as GitHub Actions’ free tier exists. This is the right shape for a hobby project that you want to last a decade.
Each scraper is a Python module that exposes one function:
def fetch_plays(hours=24):
"""Returns [{title, creator, album, image}, ...]"""
The orchestrator iterates through a PLAYLISTS dict, calls each scraper, generates an XSPF file, and writes it to disk. The workflow deploys the result. The index page links to each XSPF via a parachord://import?url=... button, wrapped in the parachord.com/go gateway for anywhere that strips custom URL schemes (like README files on GitHub).
The Messy Middle: Station APIs Are A Zoo
If you’re technically curious, the “fun” part of the project was that no two stations expose their data the same way. Here’s a partial tour:
-
KEXP has a beautiful, modern public REST API at
api.kexp.org/v2/plays/. JSON, pagination, per-track artwork. A joy to work with — except theirnextURLs silently drop thebegin_airdatefilter, so if you naïvely follow pagination you’ll scrape their entire history back to 2015 and hit a 502. There’s now a cutoff check per track and aMAX_PAGESsafety cap in the KEXP scraper to prevent this. -
KCRW has
tracklist-api.kcrw.com, organized by date (/Simulcast/date/2026/04/19). One array per day. Clean. -
WFMU has no API. Their homepage now-playing widget fetches four currently-playing streams; their RSS feed lists recent show URLs but no tracks. Instead, we fetch the RSS feed, pick shows within the last 24 hours, then scrape each show’s HTML playlist page — parsing the
<table id="drop_table">they’ve used since roughly 2003. There’s a subtle gotcha: the song-title cell contains both the visible title AND a hidden<span style="display:none">"Song" by "Artist"</span>used for JS tooltips. Naive tag-stripping concatenates them:Friday I'm in Love → "Friday I'm in Love" by "The Cure". You have to strip hidden spans and buttons before stripping remaining tags. -
WFUV publishes an RSS feed at
wfuv.org/playlist/feedwith song title in<title>and artist in<description>. Minimal but honest. -
WMBR (MIT’s station) has a custom XML endpoint called
dynamic.xmlwith a<wmbr_plays>element containing HTML-encoded HTML (yes, really). Decode once, parse the resulting<p class="recent">fragments, extract artist/title. -
WPRB, KALX, and hundreds of other non-commercial stations all use Spinitron as their playlist backend. Spinitron’s public pages embed
data-spin="{json}"attributes on each recent play, which means one shared scraper works for every Spinitron-hosted station. Adding a new one becomes a one-line config change. -
Bagel Radio started on SomaFM, migrated to their own Squarespace site in 2021, and uses SoundStack for streaming. Their playlist widget on the web is actually powered by OnlineRadioBox, which monitors the stream and publishes track metadata at
/json/{country}/{slug}/playlist/{day}. A second shared scraper covers this — which means we can now add any of the thousands of stations that OnlineRadioBox tracks with another one-line config change. -
SomaFM has
/songs/{channel}.json, beautifully simple. One scraper handles the whole network; we run two channels today (Groove Salad and Indie Pop Rocks) and can trivially add more. -
Radio Paradise has a nowplaying API that returns 100 recent tracks with album art. Best-in-class.
-
NTS Radio has a two-channel live API plus a per-show tracklist endpoint — but tracklists are DJ-submitted by hand, so some shows fill in, some don’t. Whatever’s there when the cron runs is what you get.
-
Vintage Obscura has a lovely little
recent_tracks.jsonendpoint powering their homepage. Titles come pre-formatted asArtist - Song [Country, Genre] (Year); we split on the first ` - ` and keep the trailing metadata in the track title because it’s actually useful context.
The stations that do expose playlist data tend to be the ones you’d want to listen to anyway. Public radio and community stations tend to be culturally committed to openness in a way that commercial Top 40 stations aren’t, and that turns out to be visible in their tech stacks. I dream of dates when everyone just publishes .xspfs directly from their own sites that Parachord (and any/all other player that choose to support the format) can add them.
A Small Note on the Aesthetic
The Spinbin landing page deliberately mirrors Parachord’s own light-mode design — the same #7c3aed purple, the same card shadows, the same plugin-tile shape and size. This wasn’t accidental. If Parachord is the destination for these playlists, the on-ramp should feel like part of the same world.
Each station gets a 88px rounded-square brand tile in its actual colors: KEXP teal, KCRW red, WFMU black, WPRB Princeton orange, KALX Berkeley blue, WMBR MIT crimson, and so on. They’re arranged in a grid, filterable by genre (indie, rock, eclectic, ambient, electronic, public, community, freeform, college, alternative, vintage, international), searchable by name/city/description, sortable by “Recently added” or A–Z. Same design language you’d find in Parachord’s plugin settings page — because they solve the same problem: how do you present a lot of little services, each with their own identity, in a way that feels coherent? At some point I will probably also move a version of the entire directory into Parachord itself (which is why it doesn’t have a friendly URL at the moment), but for now it felt like this was the right place to start.
Try It
- Browse: jherskowitz.github.io/spinbin
- Code: github.com/jherskowitz/spinbin
- Request a station: open an issue — if it has a public playlist feed, I’ll add it.
Click “Add to Parachord” on any card and the station shows up in your library. It’ll update tomorrow morning, and the morning after that, and the morning after that. If you run a music site and you want to publish auto-updating playlists for Parachord users, the pattern is five lines of Python and a GitHub Action.
This whole thing has taken, in total, maybe two days of work spread across a couple of evenings. Most of that was writing scrapers for stations that expose their data in 14 mutually-incompatible ways. The core idea — “turn the web into playlists” — is still as simple as it was in 2014. What’s different now is that there’s finally somewhere worthwhile for the playlists to go.
Welcome back, Spinbin.